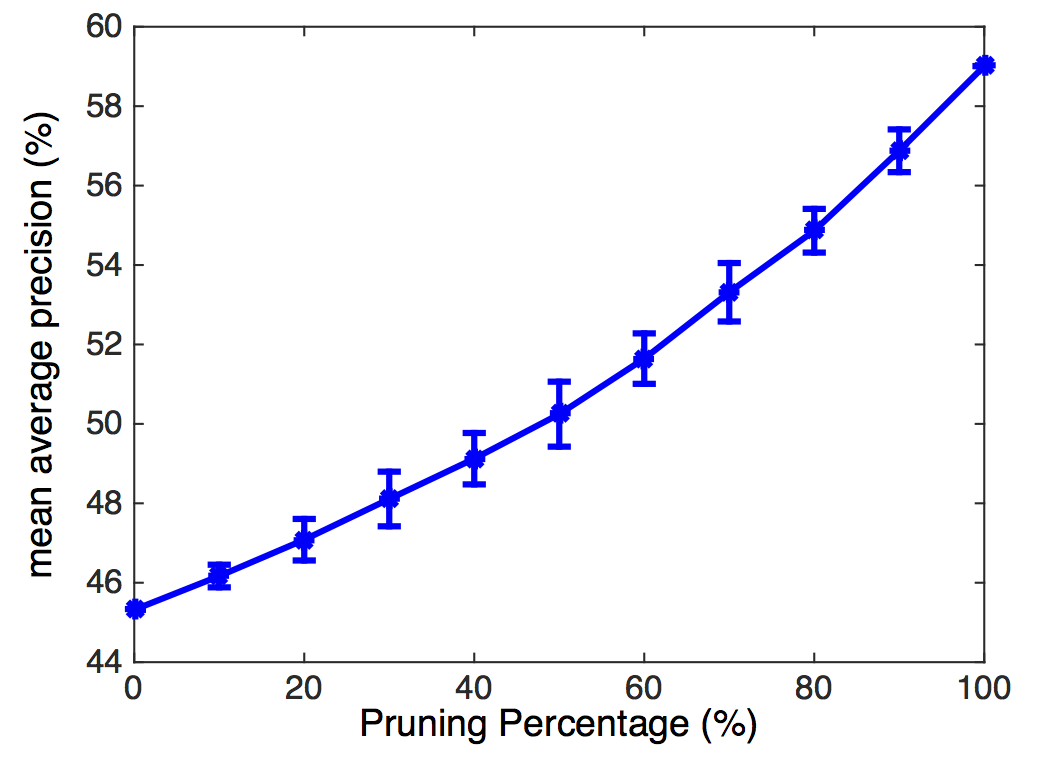
Figure 2. Does action recognition performance improve if we remove the action-irrelevant shots from training and test videos? On ActionThread dataset, the recognition performance increases as we remove more and more non-action shots using shot-level annotation. Our method for action recognition is based on Dense Trajectory Descriptors, Fisher Vector encoding, and Least-Squares SVM.
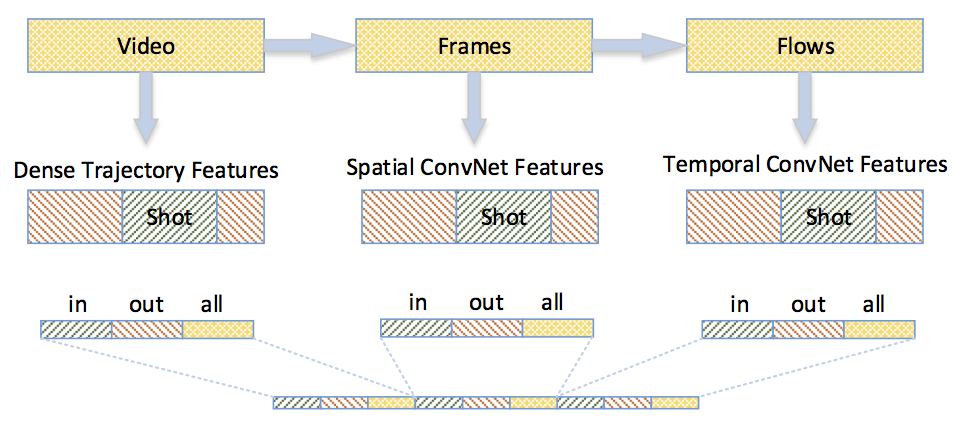
Figure 3. What features distinguish non-action shots from action shots? Many non-action shots can be identified based on the size of the human charactors, the amount of motion, and the context of this shot in a longer video sequence (e.g., part of a dialog). To capture these information for classification, we propose to combine DTDs and spatiotemporal features from a Two-stream ConvNet.
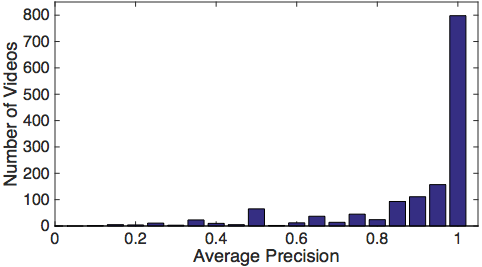
Figure 4. How good is our non-action classifier? Our classifier achieves 86.1% AP on 9,873 shots extracted from the test videos. Here we show the distribution of the APs computed for individual videos. The big propotion of the videos have the AP of 1, which means a perfect separation between action and non-action shots.
<
True Positive,
True Negative,
False Positive,
False Negative>
Figure 4. How to improve human action recognition with the non-action classifier? We propose to weight video segments based on their non-action confidence scores. The higher the non-action score the lower the weight.
More examples of weighted representation.